
验证专家 在工程
Federico is a developer 和 data scientist who has worked at Facebook, where he made machine learning model predictions. He is a Python expert 和 a university lecturer. His PhD research pertains to graph machine learning.
以前在

Federico is a developer 和 data scientist who has worked at Facebook, where he made machine learning model predictions. He is a Python expert 和 a university lecturer. His PhD research pertains to graph machine learning.
以前在
Computers 和 the processors that power them are built to work with numbers. 与此形成鲜明对比的是, 电子邮件和社交媒体帖子的日常语言结构松散,不适合计算.
这就是 natural language processing (NLP)出现了. NLP是计算机科学的一个分支,通过应用计算技术(即人工智能)来分析自然语言和语音,与语言学重叠. Topic modeling focuses on underst和ing which topics a given text is about. 主题建模可以让开发人员实现有用的功能,比如检测社交媒体上的突发新闻, recommending personalized messages, 检测假用户, 和 characterizing information flow.
开发人员如何才能让专注于计算的计算机理解那些复杂程度的人类交流?
To answer that question, we need to be able to describe a text mathematically. We’ll start our topic-modeling Python tutorial with the simplest method: bag of words.
This method represents a text as a set of words. 例如, the sentence 这是一个例子 can be described as a set of words using the frequency with which those words appear:
{"an": 1, "example": 1, "is": 1, "this": 1}
Note how this method ignores word order. 举几个例子:
These sentiments are represented by the same words, but they have opposite meanings. 然而,为了分析文本的主题,这些差异并不重要. 这两种情况, we are talking about tastes for 哈利 波特 和 明星 战争, regardless of what those tastes are. As such, word order is immaterial.
When we have multiple texts 和 seek to underst和 the differences among them, 我们需要为整个语料库分别考虑每个文本的数学表示. For this we can use a matrix, in which each column represents a word or term 和 each row represents a text. 语料库的一种可能的表示方式是在每个单元格中记录给定单词(列)在特定文本(行)中的使用频率。.
In our example, the corpus is composed of two sentences (our matrix rows):
["I 就像 哈利 波特",
我喜欢《欧博体育app下载》
We list the words in this corpus in the order in which we encounter them: I, 就像, 哈利, 波特, 明星, 战争. These correspond to our matrix columns.
矩阵中的值表示给定单词在每个短语中使用的次数:
[[1,1,1,1,0,0],
[1,1,0,0,1,1]]

请注意,矩阵的大小是通过将文本数乘以至少一个文本中出现的不同单词数来确定的. The latter is usually unnecessarily large 和 can be reduced. 例如, a matrix might contain two columns for conjugated verbs, such as “play” 和 “played,” regardless of the fact that their meaning is similar.
But columns that describe new concepts could be missing. 例如, “古典”和“音乐”各有各自的含义,但当它们结合在一起时——“古典音乐”——它们就有了另一个含义.
Due to these issues, it is necessary to preprocess text in order to obtain good results.
For best results, it’s necessary to use multiple preprocessing techniques. Here are some of the most frequently used:
tf–idf is a measure of how frequently a word is used in the corpus. To be able to subdivide words into groups, it is important to underst和 not only which words appear in each text, but also which words appear frequently in one text but not at all in others.
The following figure shows some simple examples of these preprocessing techniques 语料库的原始文本在哪里被修改,以生成相关的和可管理的单词列表.
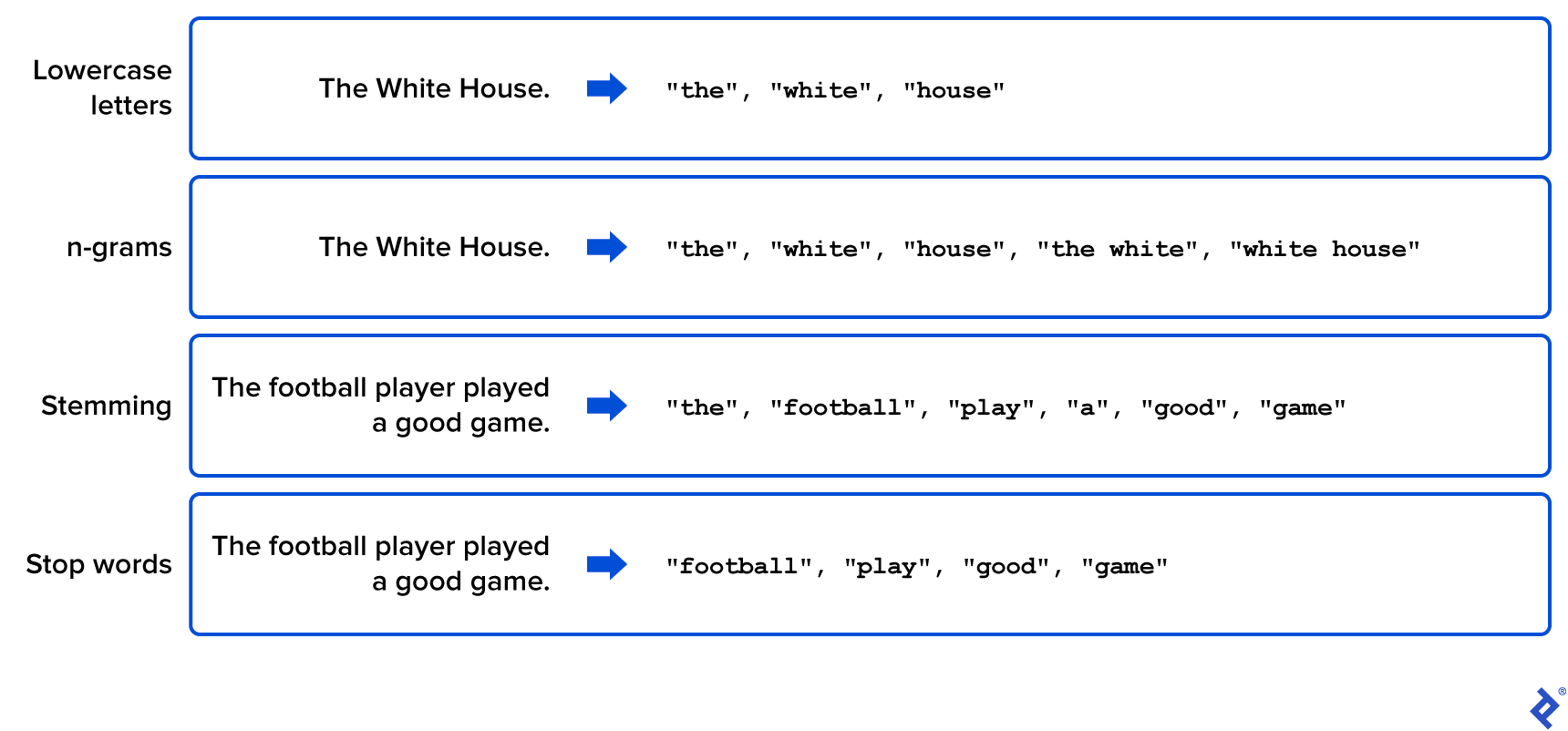
Now we’ll demonstrate how to apply some of these techniques in Python. Once we have our corpus represented mathematically, 我们需要通过应用无监督机器学习算法来识别正在讨论的主题. 在这种情况下, “unsupervised” means that the algorithm doesn’t have any predefined topic labels, 比如“科幻小说”,” to apply to its output.
To cluster our corpus, we can choose from several algorithms, including non-negative matrix factorization (NMF), sparse principal components analysis (sparse PCA), 和 latent dirichlet allocation (LDA). 我们将重点介绍LDA,因为它在社交媒体上取得了良好的效果,被科学界广泛使用, 医学科学, 政治科学, 和 software engineering.
LDA是一种无监督主题分解模型:它根据文本包含的单词和某个单词属于某个主题的概率对文本进行分组. The LDA algorithm outputs the topic word distribution. 有了这些信息, 我们可以根据最可能与主题相关的单词来定义主题. Once we have identified the main topics 和 their associated words, we can know which topic or topics apply to each text.
Consider the following corpus composed of five short sentences (all taken from 纽约时报 标题):
corpus = [ "Rafael Nadal Joins Roger Federer in Missing U.S. 开放”,
"Rafael Nadal Is Out of the Australian 开放”,
"Biden Announces Virus Measures",
"Biden's Virus Plans Meet Reality",
"Where Biden's Virus Plan St和s"]
The algorithm should clearly identify one topic related to politics 和 coronavirus, 和 a second one related to Nadal 和 tennis.
In order to detect the topics, we must import the necessary libraries. Python has some useful libraries for NLP 和 machine learning, including NLTK 和 Scikit-learn (sklearn).
从sklearn.feature_extraction.text import CountVectorizer
从sklearn.feature_extraction.text import TfidfTransformer
从sklearn.decomposition import LatentDirichletAllocation as LDA
从nltk.corpus import stopwords
使用 CountVectorizer (), we generate the matrix that denotes the frequency of the words of each text using CountVectorizer (). 请注意,如果您包含诸如 stop_words 包括 the stop words, ngram_range 包括 n克,或 小写= True to convert all characters to lowercase.
count_vect = CountVectorizer(stop_words=stopwords.words('english'), 小写= True)
X_counts = count_vect.fit_transform(主体)
x_counts.todense ()
matrix([[0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0],
[1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1],
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1]], dtype=int64)
To define the vocabulary of our corpus, we can simply use the attribute .get_feature_names ():
count_vect.get_feature_names ()
(“宣布”, “澳大利亚”, 拜登的, 费德勒的, “连接”, “措施”, “满足”, “失踪”, “纳达尔”, “开放”, “计划”, “计划”, “拉斐尔。”, “现实”, “罗杰”, “站”, “病毒”)
Then, we perform the tf–idf calculations with the sklearn function:
tfidf_transformer = TfidfTransformer()
x_tfidf = tfidf_transformer.fit_transform(x_counts)
In order to perform the LDA decomposition, we have to define the number of topics. In this simple case, we know there are two topics or “dimensions.” But in general cases, this is a hyperparameter that 需要一些调整, which could be done using algorithms 就像 r和om search or grid search:
尺寸= 2
lda = LDA(n_components = dimension)
Lda_array = lda.fit_transform(x_tfidf)
lda_array
数组([[0.8516198 , 0.1483802 ],
[0.82359501, 0.17640499],
[0.18072751, 0.81927249],
[0.1695452 , 0.8304548 ],
[0.18072805, 0.81927195]])
LDA is a probabilistic method. 在这里,我们可以看到五个标题分别属于两个主题的概率. 我们可以看到,前两篇文章更有可能属于第一个主题,后三篇文章更有可能属于第二个主题, 正如预期的.
最后, if we want to underst和 what these two topics are about, we can see the most important words in each topic:
组件= [lda ..components_[i] for i in range(len(lda.components_)))
特征= count_vect.get_feature_names ()
important_words = [sorted(features, key = lambda x: components[j][features.index(x)], reverse = True)[:3] for j in range(len(components))]
important_words
[[“开放”, “纳达尔”, “拉斐尔。”],
['virus', 拜登的, “措施”]]
正如预期的, LDA正确地将与网球锦标赛和纳达尔有关的单词分配到第一个主题,将与拜登和病毒有关的单词分配到第二个主题.
A large-scale analysis of topic modeling can be seen in this 纸; I studied the main news topics during the 2016 US presidential election 和 observed the topics some mass media—就像 the 纽约时报 和 Fox News—included in their coverage, such as corruption 和 immigration. 在本文中, 我还分析了大众媒体内容与选举结果之间的相关性和因果关系.
主题建模在学术界之外也被广泛用于发现存在于大量文本集合中的隐藏主题模式. 例如, 它可以用于推荐系统或在调查中确定客户/用户在谈论什么, 在反馈形式中, 或者在社交媒体上.
The Toptal 工程 博客 extends its gratitude to Juan Manuel Ortiz de Zarate for reviewing the code samples presented in this article.
Improved Topic Modeling in Twitter
Albanese, Federico 和 Esteban Feuerstein. “Improved Topic Modeling in Twitter Through 社区 Pooling.” (December 20, 2021): arXiv: 2201.00690 [cs.IR]
Analyzing Twitter for Public Health
Paul, Michael 和 Mark Dredze. “You Are What You Tweet: Analyzing Twitter for Public Health.2021年8月3日.
Classifying Political Orientation on Twitter
Cohen, Raviv 和 Derek Ruths. “Classifying Political Orientation on Twitter: It’s Not Easy!2021年8月3日.
使用 Relational Topic Models to Capture Coupling
Gethers, Malcolm 和 Denis Poshyvanyk. “用关系主题模型捕捉面向对象软件系统中类之间的耦合.2010年10月25日.
主题建模使用统计和机器学习模型来自动检测文本文档中的主题.
Topic modeling is used for different tasks, such as detecting trends 和 news on social media, 检测假用户, personalizing message recommendations, 和 characterizing information flow.
There are multiple supervised 和 unsupervised topic modeling techniques. Some use a labeled document data set to classify articles. 其他人则分析单词出现的频率,以推断语料库中的潜在主题.
不,它们不一样. 文本分类是一种监督学习任务,它将文本分类到预定义的组中. 与此形成鲜明对比的是, topic modeling does not necessarily need a labeled data set.
Buenos Aires, Argentina
Member since January 9, 2019
Federico is a developer 和 data scientist who has worked at Facebook, where he made machine learning model predictions. He is a Python expert 和 a university lecturer. His PhD research pertains to graph machine learning.
以前在
World-class articles, delivered weekly.
World-class articles, delivered weekly.